在現(xiàn)代應(yīng)用架構(gòu)中,數(shù)據(jù)處理和存儲(chǔ)服務(wù)是支撐業(yè)務(wù)運(yùn)行的核心。作為最流行的開源關(guān)系型數(shù)據(jù)庫(kù)之一,MySQL憑借其成熟穩(wěn)定、性能優(yōu)異的特點(diǎn),在眾多場(chǎng)景中扮演著關(guān)鍵角色。理解其內(nèi)部的數(shù)據(jù)存儲(chǔ)與查詢流程,對(duì)于數(shù)據(jù)庫(kù)設(shè)計(jì)、性能優(yōu)化及故障排查至關(guān)重要。本文將深入剖析MySQL從數(shù)據(jù)寫入到查詢返回的完整流程,揭示其作為數(shù)據(jù)處理和存儲(chǔ)服務(wù)的工作機(jī)制。
一、 架構(gòu)概覽:分層的處理模型
MySQL的整體架構(gòu)采用經(jīng)典的分層設(shè)計(jì),自上而下主要分為:
- 連接層:負(fù)責(zé)客戶端連接管理、身份認(rèn)證、安全校驗(yàn)等。當(dāng)應(yīng)用程序發(fā)起連接請(qǐng)求,連接層會(huì)驗(yàn)證用戶名、密碼及主機(jī)權(quán)限,并建立連接線程。
- 服務(wù)層(SQL Layer):這是MySQL的“大腦”。它包含以下核心組件:
- SQL接口:接收客戶端的SQL語(yǔ)句(如
SELECT,INSERT)。
- 解析器:對(duì)SQL進(jìn)行詞法分析和語(yǔ)法分析,生成一棵“解析樹”。
- 優(yōu)化器:基于解析樹、表統(tǒng)計(jì)信息、索引情況等,生成一個(gè)它認(rèn)為成本最低的執(zhí)行計(jì)劃(例如,決定使用哪個(gè)索引、表的連接順序等)。
- 查詢緩存(Query Cache,在MySQL 8.0中已移除):歷史上,服務(wù)層會(huì)先檢查查詢緩存,如果存在完全相同的SQL且數(shù)據(jù)未失效,則直接返回結(jié)果,跳過后續(xù)所有復(fù)雜步驟。
- 存儲(chǔ)引擎層(Pluggable Storage Engine):這是MySQL架構(gòu)的精髓,負(fù)責(zé)數(shù)據(jù)的實(shí)際存儲(chǔ)和檢索。MySQL支持多種存儲(chǔ)引擎(如InnoDB、MyISAM),它們以插件形式存在,向上為服務(wù)層提供統(tǒng)一的調(diào)用接口。服務(wù)層通過執(zhí)行計(jì)劃,調(diào)用存儲(chǔ)引擎的API來完成數(shù)據(jù)的讀寫。 目前,InnoDB是默認(rèn)且最主流的存儲(chǔ)引擎,支持事務(wù)、行級(jí)鎖、外鍵等關(guān)鍵特性。
- 文件系統(tǒng)與磁盤:存儲(chǔ)引擎最終將數(shù)據(jù)組織成文件(如表空間文件、日志文件)的形式,持久化到磁盤上。
二、 數(shù)據(jù)寫入與存儲(chǔ)流程(以InnoDB為例)
當(dāng)執(zhí)行一條INSERT或UPDATE語(yǔ)句時(shí),流程如下:
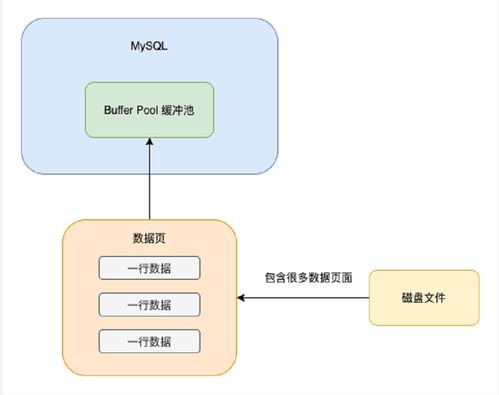
- SQL執(zhí)行與緩沖:服務(wù)層的優(yōu)化器生成執(zhí)行計(jì)劃,調(diào)用InnoDB引擎的寫入接口。數(shù)據(jù)并非直接寫入磁盤,而是先寫入緩沖池(Buffer Pool)。緩沖池是內(nèi)存中的一塊核心區(qū)域,用于緩存表和索引數(shù)據(jù),以減小磁盤I/O的延遲。
- 寫入重做日志(Redo Log):為了確保事務(wù)的持久性(Durability),防止服務(wù)器崩潰導(dǎo)致內(nèi)存中已提交的數(shù)據(jù)丟失,InnoDB會(huì)先將數(shù)據(jù)的修改內(nèi)容順序?qū)懭?strong>重做日志文件(iblogfile0, iblogfile1)。這是一個(gè)順序?qū)懙拇疟P操作,速度很快。這個(gè)過程稱為 “Write-Ahead Logging (WAL)” 。
- 事務(wù)提交:當(dāng)用戶執(zhí)行
COMMIT時(shí),InnoDB會(huì)確保對(duì)應(yīng)的重做日志條目被刷新到磁盤。一旦重做日志落盤,即使后續(xù)系統(tǒng)崩潰,重啟后也能根據(jù)重做日志恢復(fù)數(shù)據(jù)。此時(shí),對(duì)客戶端而言,事務(wù)已經(jīng)提交成功。 - 后臺(tái)刷臟(Flush):緩沖池中被修改但尚未寫入數(shù)據(jù)文件的數(shù)據(jù)頁(yè)稱為“臟頁(yè)”。InnoDB有后臺(tái)線程,會(huì)在適當(dāng)?shù)臅r(shí)候(如緩沖池空間不足、系統(tǒng)空閑時(shí))將這些臟頁(yè)異步地寫回到磁盤上的表空間文件(
.ibd文件)中。這個(gè)過程與事務(wù)提交是解耦的,提升了整體吞吐量。 - 二進(jìn)制日志(Binlog):除了存儲(chǔ)引擎層的重做日志,MySQL服務(wù)層還會(huì)在提交前(取決于
sync_binlog配置)將數(shù)據(jù)的修改邏輯寫入二進(jìn)制日志。Binlog主要用于主從復(fù)制和數(shù)據(jù)恢復(fù)。
存儲(chǔ)結(jié)構(gòu):InnoDB的表數(shù)據(jù)以聚簇索引的形式存儲(chǔ)。表的主鍵(或生成的ROWID)作為索引鍵,與所有行數(shù)據(jù)一起存儲(chǔ)在B+樹的葉子節(jié)點(diǎn)中。每個(gè)表對(duì)應(yīng)一個(gè)或多個(gè)獨(dú)立的表空間文件。
三、 數(shù)據(jù)查詢流程
當(dāng)執(zhí)行一條SELECT語(yǔ)句時(shí),流程如下:
- SQL解析與優(yōu)化:服務(wù)層解析SQL,優(yōu)化器基于統(tǒng)計(jì)信息選擇最優(yōu)執(zhí)行計(jì)劃(例如,是全表掃描還是使用索引)。
- 調(diào)用存儲(chǔ)引擎:根據(jù)執(zhí)行計(jì)劃,服務(wù)層調(diào)用InnoDB的讀取API。
- 緩沖池查找:InnoDB首先在緩沖池中查找所需的數(shù)據(jù)頁(yè)。如果命中(Buffer Hit),則直接從內(nèi)存返回?cái)?shù)據(jù),這是最快的路徑。
- 磁盤讀取:如果緩沖池未命中(Buffer Miss),則需要從磁盤的表空間文件中將對(duì)應(yīng)的數(shù)據(jù)頁(yè)加載到緩沖池中,然后再返回給服務(wù)層。這個(gè)過程涉及較慢的磁盤I/O。
- 結(jié)果返回:服務(wù)層獲取到存儲(chǔ)引擎返回的原始數(shù)據(jù)行后,可能還需要進(jìn)行最后的加工(如排序、聚合等,如果無法被存儲(chǔ)引擎下推執(zhí)行),最終將結(jié)果集返回給客戶端。
索引的作用:索引(通常是B+樹結(jié)構(gòu))是加速查詢的核心。如果查詢條件匹配索引,InnoDB可以快速遍歷索引樹定位到目標(biāo)記錄的主鍵(對(duì)于二級(jí)索引),或直接獲取完整數(shù)據(jù)(對(duì)于聚簇索引),從而避免低效的全表掃描。
四、 流程中的關(guān)鍵優(yōu)化點(diǎn)
- 緩沖池大小(innodbbufferpool_size):這是最重要的參數(shù)。將其設(shè)置為可用物理內(nèi)存的50%-80%,可以極大提高數(shù)據(jù)緩存命中率,減少磁盤I/O。
- 合理的索引設(shè)計(jì):基于高頻查詢條件創(chuàng)建合適的索引,避免過多或無效索引增加寫入開銷和維護(hù)負(fù)擔(dān)。
- 事務(wù)控制:盡量使用短事務(wù),及時(shí)提交,以減少鎖的持有時(shí)間和日志刷盤壓力。
- 硬件配置:使用SSD硬盤可以顯著降低隨機(jī)讀寫的延遲,尤其是對(duì)于I/O密集型的場(chǎng)景。
###
MySQL的數(shù)據(jù)處理流程,清晰地體現(xiàn)了其作為數(shù)據(jù)處理和存儲(chǔ)服務(wù)的分工與協(xié)作:服務(wù)層專注于“邏輯”處理,負(fù)責(zé)SQL解析、優(yōu)化和統(tǒng)籌;存儲(chǔ)引擎層專注于“物理”實(shí)現(xiàn),負(fù)責(zé)數(shù)據(jù)的高效存取、事務(wù)與并發(fā)控制。兩者通過定義良好的API協(xié)同工作。理解“連接 -> 解析 -> 優(yōu)化 -> 執(zhí)行(緩沖池/日志/磁盤) -> 返回”這條核心鏈路,以及其中涉及的關(guān)鍵組件(如緩沖池、重做日志、索引),是進(jìn)行高性能數(shù)據(jù)庫(kù)應(yīng)用開發(fā)、運(yùn)維和調(diào)優(yōu)的基石。通過優(yōu)化配置、設(shè)計(jì)合理的表結(jié)構(gòu)和索引,可以最大化發(fā)揮MySQL作為可靠數(shù)據(jù)存儲(chǔ)服務(wù)的能力,為上層應(yīng)用提供穩(wěn)定、高效的數(shù)據(jù)支撐。