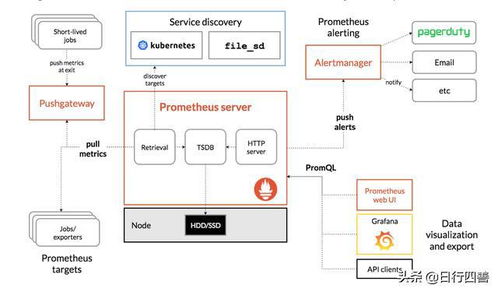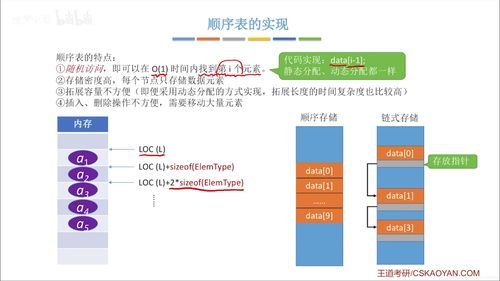
數據結構是計算機科學中組織和存儲數據的核心理論與方法,是構建高效數據處理與存儲服務的基石。無論是傳統數據庫,還是現代云計算、大數據平臺,其底層都依賴于精心設計的數據結構。理解并掌握數據結構,如同掌握了構建高效、可靠數字服務的“內功心法”。
一、數據結構:數據處理服務的效率引擎
數據處理服務的核心任務是高效地進行數據的增、刪、改、查。不同的數據結構為此提供了不同的性能特征:
- 線性結構(如數組、鏈表):是數據存儲的基本單元。數組支持隨機訪問,適合頻繁查找;鏈表支持高效插入刪除,是動態數據集合的基礎。
- 樹形結構(如二叉樹、B樹、B+樹):是數據庫索引的支柱。B+樹因其平衡性和順序訪問特性,被廣泛應用于關系型數據庫(如MySQL)的索引實現中,極大加速了范圍查詢和數據檢索。
- 哈希結構:通過哈希函數將鍵直接映射到存儲位置,提供近乎O(1)時間復雜度的查找,是緩存系統(如Redis)、鍵值存儲和快速去重的核心。
二、數據結構:存儲服務的組織藍圖
數據如何持久化存儲并快速定位,直接決定了存儲服務的性能與可靠性。
- 文件與磁盤管理:操作系統中的文件系統(如EXT4, NTFS)使用索引節點(inode)等數據結構來管理磁盤塊,記錄文件元數據和物理位置。
- 數據庫存儲引擎:現代數據庫的存儲引擎(如InnoDB)將表數據以B+樹索引的形式組織在頁(Page)中,頁是磁盤與內存交互的基本單位。這種結構保證了數據在磁盤上的有序性,優化了I/O效率。
- 分布式存儲:在大數據與云存儲場景中,如Google的Bigtable、Apache HBase,使用類似“排序字符串表”(SSTable)的結構存儲數據,并結合布隆過濾器(Bloom Filter)等概率數據結構快速判斷數據是否存在,減少不必要的磁盤訪問。
三、王道實踐:從理論到服務架構
掌握數據結構的“王道”,在于深刻理解其時空復雜度,并能根據服務需求進行選型和組合。
- 設計緩存服務:結合哈希表(快速查找)與雙向鏈表(實現LRU淘汰策略),可以構建一個高效的LRU緩存。
- 設計實時排行榜:使用跳表(Skip List)或平衡樹(如紅黑樹),可以在動態數據流中高效維護有序集合并支持快速排名查詢。
- 保障服務高可用:在分布式系統中,一致性哈希數據結構能有效解決節點擴容縮容時的數據重新分配問題,最小化數據遷移量,提升服務的穩定性和可擴展性。
###
數據結構并非抽象的理論,而是貫穿于每一個數據處理與存儲服務背后的設計靈魂。從內存中的高速計算到磁盤上的持久化組織,再到分布式環境下的協同管理,優秀的數據結構選擇與實現是服務達到高性能、高可靠、高可擴展目標的根本保障。深入理解數據結構,就是握住了開啟高效數字世界大門的鑰匙。